资源推荐
3 分钟阅读
Kubernetes 用户在创建应用资源时常常是基于经验值来设置 request 和 limit。通过资源推荐的算法分析应用的真实用量推荐更合适的资源配置,您可以参考并采纳它提升集群的资源利用率。
动机
Kubernetes 中 Request 定义了 Pod 运行需要的最小资源量,Limit 定义了 Pod 运行可使用的最大资源量,应用的资源利用率 Utilization = 资源用量 Usage / Request 。不合理的资源利用率有以下两种情况:
- 利用率过低:因为不清楚配置多少资源规格可以满足应用需求,或者是为了应对高峰流量时的资源消耗诉求,常常将 Request 设置得较大,这样就导致了过低的利用率,造成了浪费。
- 利用率过高:由于高峰流量的业务压力,或者错误的资源配置,导致利用率过高,CPU 利用率过高时会引发更高的业务延时,内存利用率过高超过 Limit 会导致 Container 被 OOM Kill,影响业务的稳定。
下图展示了一个利用率过低的例子,该 Pod 的历史使用量的峰值与它的申请量 Request 之间,有30%的资源浪费。
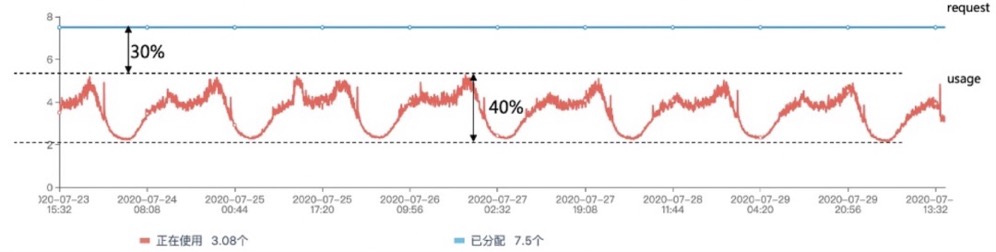
资源推荐尝试通过基于历史真实用量的分析降低用户配置容器规格的复杂度。
推荐示例
一个简单的资源推荐 yaml 文件如下:
kind: Recommendation
apiVersion: analysis.crane.io/v1alpha1
metadata:
name: workloads-rule-resource-flzbv
namespace: crane-system
labels:
analysis.crane.io/recommendation-rule-name: workloads-rule
analysis.crane.io/recommendation-rule-recommender: Resource
analysis.crane.io/recommendation-rule-uid: 18588495-f325-4873-b45a-7acfe9f1ba94
analysis.crane.io/recommendation-target-kind: Deployment
analysis.crane.io/recommendation-target-name: load-test
analysis.crane.io/recommendation-target-version: v1
app: craned
app.kubernetes.io/instance: crane
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: crane
app.kubernetes.io/version: v0.7.0
helm.sh/chart: crane-0.7.0
ownerReferences:
- apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
name: workloads-rule
uid: 18588495-f325-4873-b45a-7acfe9f1ba94
controller: false
blockOwnerDeletion: false
spec:
targetRef:
kind: Deployment
namespace: crane-system
name: craned
apiVersion: apps/v1
type: Resource
completionStrategy:
completionStrategyType: Once
adoptionType: StatusAndAnnotation
status:
recommendedValue:
resourceRequest:
containers:
- containerName: craned
target:
cpu: 150m
memory: 256Mi
- containerName: dashboard
target:
cpu: 150m
memory: 256Mi
targetRef: {}
recommendedInfo: >-
{"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}}]}}}}
currentInfo: >-
{"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"500m","memory":"512Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"200m","memory":"256Mi"}}}]}}}}
action: Patch
conditions:
- type: Ready
status: 'True'
lastTransitionTime: '2022-11-29T04:07:44Z'
reason: RecommendationReady
message: Recommendation is ready
lastUpdateTime: '2022-11-30T03:07:49Z'
在该示例中:
- 推荐的 TargetRef 指向 crane-system 的 Deployment:craned
- 推荐类型为资源推荐
- adoptionType 是 StatusAndAnnotation,表示将推荐结果展示在 recommendation.status 和 Deployment 的 Annotation
- recommendedInfo 显示了推荐的资源配置(recommendedValue 已经 deprecated),currentInfo 显示了当前的资源配置,格式是 Json ,可以通过 Kubectl Patch 将推荐结果更新到 TargetRef
如何使用资源推荐请参考:推荐框架
实现原理
资源推荐按以下步骤完成一次推荐过程:
- 通过监控数据,获取 Workload 过去一周的 CPU 和 Memory 历史用量。
- 基于历史用量通过 VPA Histogram 取 P99 百分位后再乘以放大系数
- OOM 保护:如果容器存在历史的 OOM 事件,则考虑 OOM 时的内存适量增大内存推荐结果
- 资源规格规整:按指定的容器规格对推荐结果向上取整
基本原理是基于历史的资源用量,将 Request 配置成略高于历史用量的最大值并且考虑 OOM,Pod 规格等因素。
VPA 算法
资源推荐的核心思想是基于历史资源用量推荐合理的资源配置,我们采用了社区 VPA Histogram 算法来实现。VPA 算法将历史的资源用量放到直方图中,找到资源用量的 P99 百分数,将百分数乘以放大系数作为推荐值。
VPA 算法的 output 是 cpu、内存指标的 P99 用量。为了给应用预留 buffer,推荐结果还会乘以放大系数。资源推荐支持两种方式配置放大系数:
- 扩大比例:推荐结果=P99用量 * (1 + 放大系数),对应配置:cpu-request-margin-fraction 和 mem-request-margin-fraction
- 目标峰值利用率:推荐结果=P99用量/目标峰值利用率,对应配置:cpu-target-utilization 和 mem-target-utilization
在您有应用的目标峰值利用率目标时,推荐使用目标峰值利用率方式放大推荐结果。
OOM 保护
Craned 运行了单独的组件 OOMRecorder ,它记录了集群中 container OOM 的事件,资源推荐会读取 OOM 事件获取 OOM 时刻的内存使用,将内存使用乘以放大系数后与 VPA 的内存推荐结果比较,取较大值
资源规格规整
在 Kubernetes Serverless 中,Pod 的 cpu、内存规格是预设的,资源推荐支持对推荐结果按预设的资源规格向上取整,例如,基于历史用量的 cpu 推荐值为0.125核,资源规格规整后向上取整后为 0.25核。用户也可以通过修改规格配置来满足自己环境的规格需求。
通过 Prometheus Metric 监控推荐结果
推荐资源的推荐结果会记录到 Metric:crane_analysis_resource_recommendation
如何验证推荐结果的准确性
用户可以通过以下 Prom query 得到 Workload Container 的资源用量,推荐值会略高于历史用量的最大值并且考虑 OOM,Pod 规格等因素。
以 crane-system 的 Deployment Craned 为例,用户可以将 container, namespace, pod 换成希望验证的推荐 TargetRef。
irate(container_cpu_usage_seconds_total{container!="POD",namespace="crane-system",pod=~"^craned.*$",container="craned"}[3m]) # cpu usage
container_memory_working_set_bytes{container!="POD",namespace="crane-system",pod=~"^craned.*$",container="craned"} # memory usage
支持推荐的资源类型
默认支持 StatefulSet 和 Deployment,但是支持所有实现了 Scale SubResource 的 Workload。
参数配置
| 配置项 | 默认值 | 描述 |
|---|---|---|
| cpu-sample-interval | 1m | 请求 CPU 监控数据的 Metric 采样点时间间隔 |
| cpu-request-percentile | 0.99 | CPU 百分位值 |
| cpu-request-margin-fraction | 0.15 | CPU 推荐值扩大系数,0.15指推荐值乘以 1.15 |
| cpu-target-utilization | 1 | CPU 目标利用率,0.8 指推荐值除以 0.8 |
| cpu-model-history-length | 168h | CPU 历史监控数据的时间 |
| mem-sample-interval | 1m | 请求 Memory 监控数据的 Metric 采样点时间间隔 |
| mem-request-percentile | 0.99 | Memory 百分位值 |
| mem-request-margin-fraction | 0.15 | Memory 推荐值扩大系数,0.15指推荐值乘以 1.15 |
| mem-target-utilization | 1 | Memory 目标利用率,0.8 指推荐值除以 0.8 |
| specification | false | 是否开启资源规格规整 |
| specification-config | "" | 资源规格,格式类似:2c4g,4c8g,2c5g,2c1g,0.25c0.25g,0.5c1g,4c16g,详细的默认配置请见下方表格 |
| oom-protection | true | 是否开启 OOM 保护 |
| oom-history-length | 168h | OOM 历史事件的事件,过期事件会被忽略 |
| oom-bump-ratio | 1.2 | OOM 内存放大系数 |
| cpu-histogram-bucket-size | 0.1 | 均衡桶的大小,同时也等于cpu推荐的最小值 |
| cpu-histogram-max-value | 100 | 均衡桶的最大值,同时也等于cpu推荐的最大值 |
| mem-histogram-bucket-size | 104857600 | 均衡桶的大小,同时也等于mem推荐的最小值 |
| mem-histogram-max-value | 104857600000 | 均衡桶的最大值,同时也等于mem推荐的最大值 |
如何更新推荐的配置请参考:推荐框架
默认的资源机型规格配置
| CPU(核) | Memory(GBi) |
|---|---|
| 0.25 | 0.25 |
| 0.25 | 0.5 |
| 0.25 | 1 |
| 0.5 | 0.5 |
| 0.5 | 1 |
| 1 | 1 |
| 1 | 2 |
| 1 | 4 |
| 1 | 8 |
| 2 | 2 |
| 2 | 4 |
| 2 | 8 |
| 2 | 16 |
| 4 | 4 |
| 4 | 8 |
| 4 | 16 |
| 4 | 32 |
| 8 | 8 |
| 8 | 16 |
| 8 | 32 |
| 8 | 64 |
| 16 | 32 |
| 16 | 64 |
| 16 | 128 |
| 32 | 64 |
| 32 | 128 |
| 32 | 256 |
| 64 | 128 |
| 64 | 256 |