副本数推荐
2 分钟阅读
Kubernetes 用户在创建应用资源时常常是基于经验值来设置副本数。通过副本数推荐的算法分析应用的真实用量推荐更合适的副本配置,您可以参考并采纳它提升集群的资源利用率。
动机
Kubernetes 工作负载的副本数可以控制 Pod 的数量进行快速的伸缩。然而,如何设置副本数量一直以来是困扰应用管理员的问题,副本数过多会导致大量的资源浪费,而过低的副本数又可能会存在稳定性问题。
社区的 HPA 提供了一种基于负载的动态伸缩机制,Crane 的 EHPA 基于 HPA 实现了基于预测的智能弹性。但是现实世界中,只有部分工作负载可以动态的水平伸缩,大量的工作负载需要在运行时保持固定的副本数。
下图展示了一个利用率过低的例子,该 Pod 的历史使用量的峰值与它的申请量 Request 之间,有30%的资源浪费。
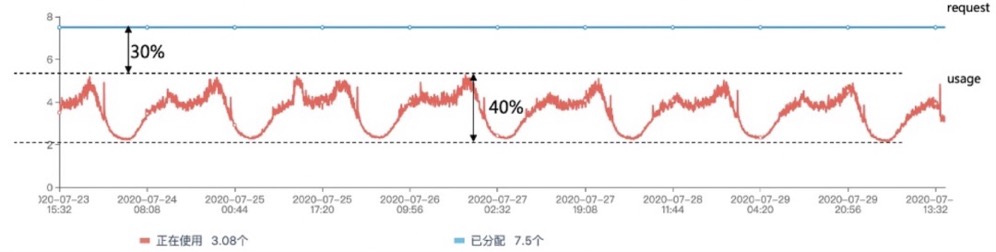
副本推荐尝试通过基于历史真实用量的分析降低用户配置工作负载副本数的复杂度。
推荐示例
一个简单的副本推荐 yaml 文件如下:
kind: Recommendation
apiVersion: analysis.crane.io/v1alpha1
metadata:
name: workloads-rule-replicas-p84jv
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
analysis.crane.io/recommendation-rule-name: workloads-rule
analysis.crane.io/recommendation-rule-recommender: Replicas
analysis.crane.io/recommendation-rule-uid: 18588495-f325-4873-b45a-7acfe9f1ba94
k8s-app: kube-dns
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: CoreDNS
ownerReferences:
- apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
name: workloads-rule
uid: 18588495-f325-4873-b45a-7acfe9f1ba94
controller: false
blockOwnerDeletion: false
spec:
targetRef:
kind: Deployment
namespace: kube-system
name: coredns
apiVersion: apps/v1
type: Replicas
completionStrategy:
completionStrategyType: Once
adoptionType: StatusAndAnnotation
status:
recommendedValue:
replicasRecommendation:
replicas: 1
targetRef: { }
recommendedInfo: '{"spec":{"replicas":1}}'
currentInfo: '{"spec":{"replicas":2}}'
action: Patch
conditions:
- type: Ready
status: 'True'
lastTransitionTime: '2022-11-28T08:07:36Z'
reason: RecommendationReady
message: Recommendation is ready
lastUpdateTime: '2022-11-29T11:07:45Z'
在该示例中:
- 推荐的 TargetRef 指向 kube-system 的 Deployment:coredns
- 推荐类型为副本推荐
- adoptionType 是 StatusAndAnnotation,表示将推荐结果展示在 recommendation.status 和 Deployment 的 Annotation
- recommendedInfo 显示了推荐的副本数(recommendedValue 已经 deprecated),currentInfo 显示了当前的副本数,格式是 Json ,可以通过 Kubectl Patch 将推荐结果更新到 TargetRef
如何使用副本推荐请参考:推荐框架
实现原理
副本推荐按以下步骤完成一次推荐过程:
- 通过监控数据,获取 Workload 过去一周的 CPU 和 Memory 历史用量。
- 用 DSP 算法预测未来一周 CPU 用量
- 分别计算 CPU 和 内存分别对应的副本数,取较大值
计算副本算法
以 CPU 举例,假设工作负载 CPU 历史用量的 P99 是10核,Pod CPU Request 是5核,目标峰值利用率是50%,可知副本数是4个可以满足峰值利用率不小于50%。
replicas := int32(math.Ceil(workloadUsage / (TargetUtilization * float64(requestTotal) )))
排除异常的工作负载
以下类型的异常工作负载不进行推荐:
- 低副本数的工作负载: 过低的副本数可能推荐需求不高,关联配置:
workload-min-replicas - 存在一定比例非 Running Pod 的工作负载: 如果工作负载的 Pod 大多不能正常运行,可能不适合弹性,关联配置:
pod-min-ready-seconds|pod-available-ratio
通过 Prometheus Metric 监控推荐结果
副本推荐结果会记录到 Metric:crane_analytics_replicas_recommendation
如何验证推荐结果的准确性
用户可以通过以下 Prom query 得到 Workload 的资源用量,将资源用量带入上面副本算法公式可验证推荐 TargetRef。
以 crane-system 的 Deployment Craned 为例,用户可以将 container, namespace, pod 换成希望验证的推荐结果。
sum(irate(container_cpu_usage_seconds_total{namespace="crane-system",pod=~"^craned-.*$",container!=""}[3m])) # cpu usage
sum(container_memory_working_set_bytes{namespace="crane-system",pod=~"^craned-.*$",container!=""}) # memory usage
支持的资源类型
默认支持 StatefulSet 和 Deployment,但是支持所有实现了 Scale SubResource 的 Workload。
参数配置
| 配置项 | 默认值 | 描述 |
|---|---|---|
| workload-min-replicas | 1 | 小于该值的工作负载不做弹性推荐 |
| pod-min-ready-seconds | 30 | 定义了 Pod 是否 Ready 的秒数 |
| pod-available-ratio | 0.5 | Ready Pod 比例小于该值的工作负载不做弹性推荐 |
| default-min-replicas | 1 | 最小 minReplicas |
| cpu-percentile | 0.95 | 历史 CPU 用量的 Percentile |
| mem-percentile | 0.95 | 历史内存用量的 Percentile |
| cpu-target-utilization | 0.5 | CPU 目标峰值利用率 |
| mem-target-utilization | 0.5 | 内存目标峰值利用率 |
如何更新推荐的配置请参考:推荐框架