精细化调度器:一个感知节点资源拓扑的调度插件
2 分钟阅读
总览
现代多核服务器大多采用非统一内存访问架构(英语:Non-uniform memory access,简称NUMA)来提高硬件的可伸缩性。NUMA是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
在 Kubernetes 中,调度是指将 Pod 放置到合适的节点上,一个节点会运行多个Pod。因此,调度器的调度粒度为节点级别,并不感知和考虑节点硬件拓扑的存在。在某些延迟敏感的场景下,可能希望Kubernetes为Pod分配拓扑最优的节点和硬件,以提升硬件利用率和程序性能。
同时,在某些复杂场景下,部分的Pod属于CPU密集型工作负载,Pod之间会争抢节点的CPU资源。当争抢剧烈的时候,Pod会在不同的CPU Core之间进行频繁的切换,更糟糕的是在NUMA Node之间的切换。这种大量的上下文切换,会影响程序运行的性能。
Kubernetes中虽然有Topology Manager来管理节点资源的拓扑对齐,但是没有与调度器联动,导致调度结果和设备资源分配结果可能不一致。
为了解决这一问题,资源拓扑感知调度给予了精细调度的能力,将调度的粒度扩展到设备级别。
设计细节
架构
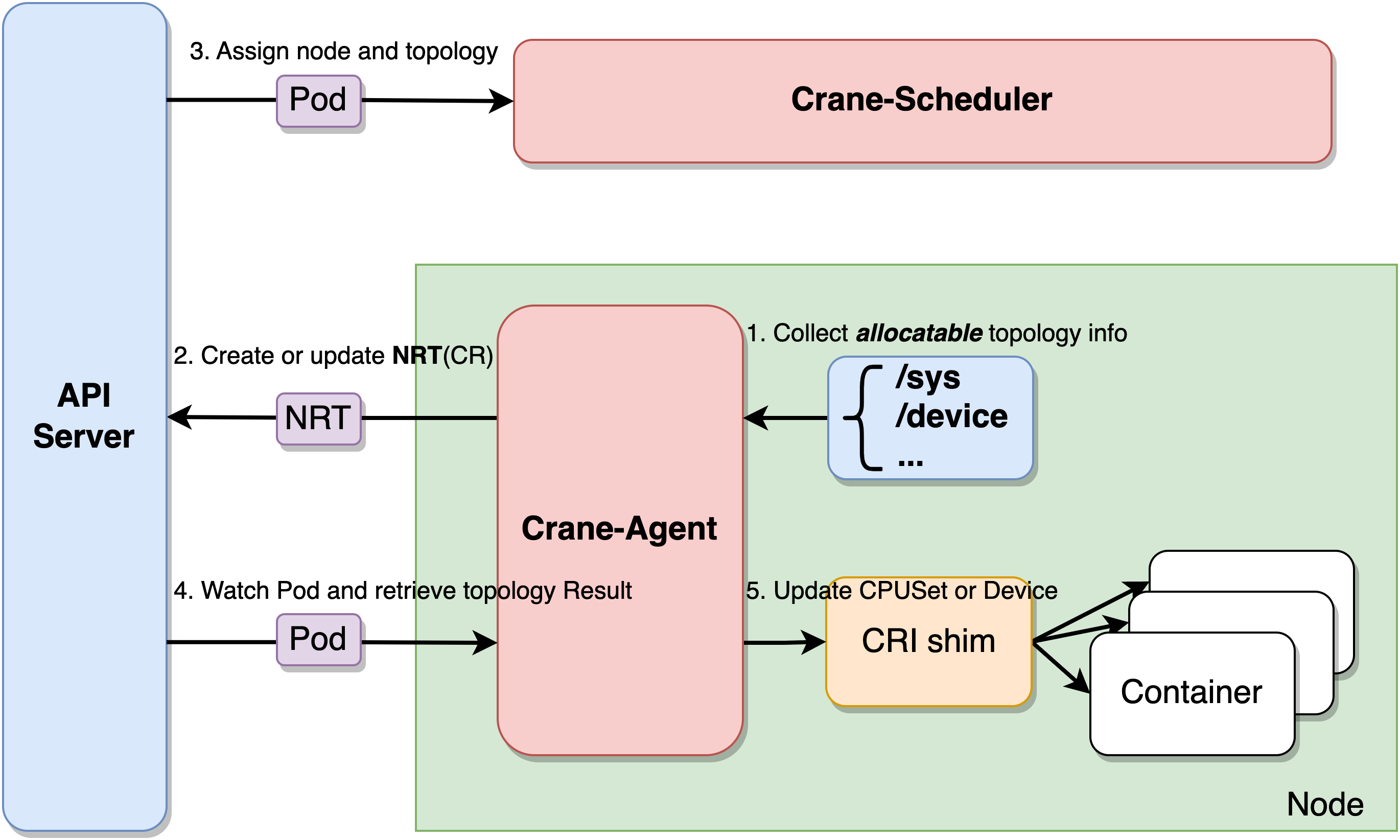
Crane-Scheduler和Crane-Agent配合工作,完成拓扑感知调度与资源分配的工作。
Crane-Agent从节点采集资源拓扑,包括NUMA、Socket、设备等信息,汇总到NodeResourceTopology这个自定义资源对象中。
Crane-Scheduler在调度时会参考节点的NodeResourceTopology对象获取到节点详细的资源拓扑结构,在调度到节点的同时还会为Pod分配拓扑资源,并将结果写到Pod的annotations中。
Crane-Agent在节点上Watch到Pod被调度后,从Pod的annotations中获取到拓扑分配结果,并按照用户给定的CPU绑定策略进行CPUSet的细粒度分配。
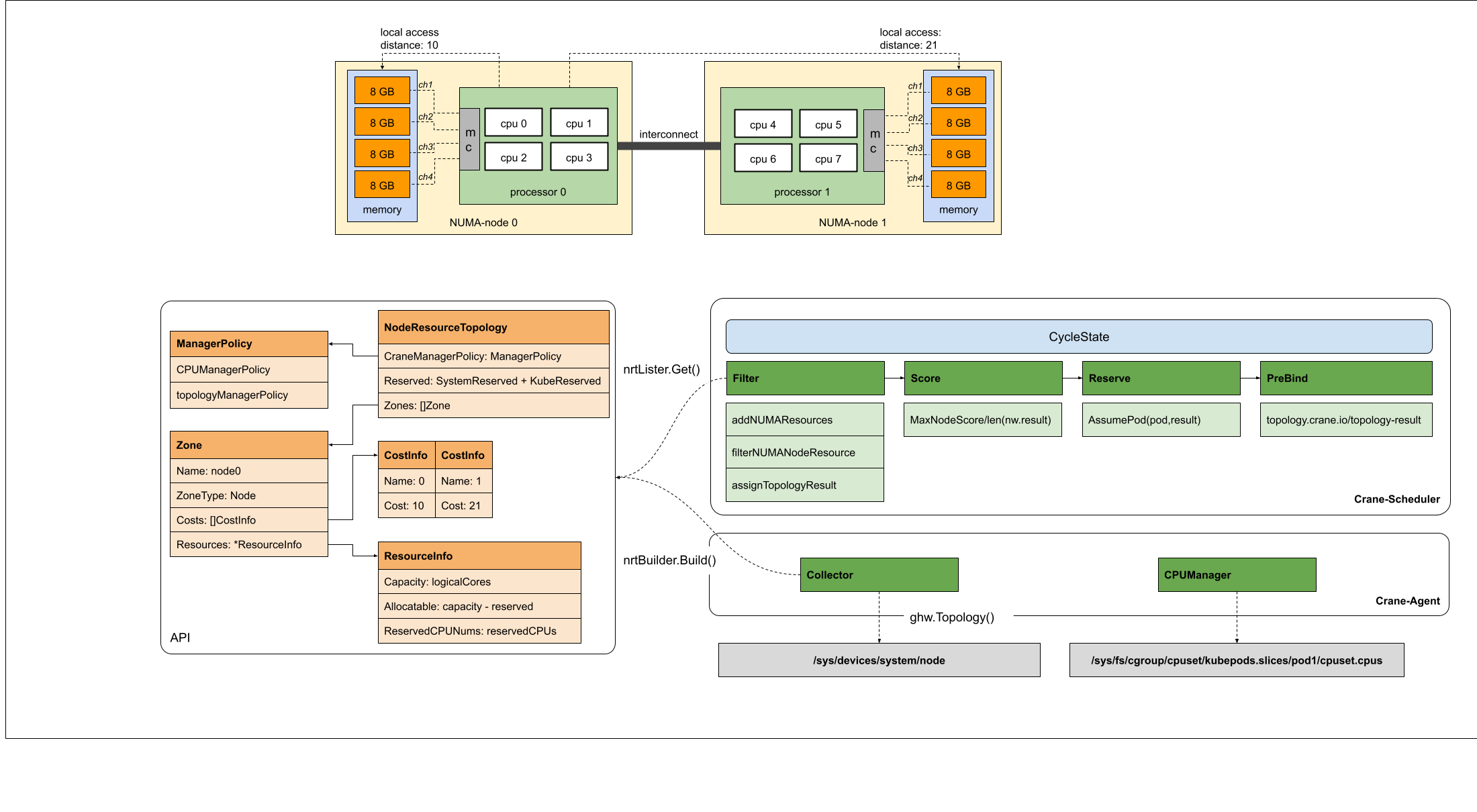
CPU分配策略
Crane中提供了四种CPU分配策略,分别如下:
- none:该策略不进行特别的CPUSet分配,Pod会使用节点CPU共享池。
- exclusive:该策略对应kubelet的static策略,Pod会独占CPU核心,其他任何Pod都无法使用。
- numa:该策略会指定NUMA Node,Pod会使用该NUMA Node上的CPU共享池。
- immovable:该策略会将Pod固定在某些CPU核心上,但这些核心属于共享池,其他Pod仍可使用。
开始
安装Crane-Agent
- 参考这里安装Crane-Agent
- 在Crane-Agent启动参数中添加
--feature-gates=NodeResourceTopology=true,CraneCPUManager=true开启拓扑感知调度特性。
安装Crane-Scheduler
- 备份
/etc/kubernetes/manifests/kube-scheduler.yaml
cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/
- 通过修改 kube-scheduler 的配置文件(
scheduler-config.yaml) 启用动态调度插件并配置插件参数:
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "REPLACE_ME_WITH_KUBE_CONFIG_PATH"
profiles:
- schedulerName: default-scheduler
plugins:
preFilter:
enabled:
- name: NodeResourceTopologyMatch
filter:
enabled:
- name: NodeResourceTopologyMatch
score:
enabled:
- name: NodeResourceTopologyMatch
weight: 2
reserve:
enabled:
- name: NodeResourceTopologyMatch
preBind:
enabled:
- name: NodeResourceTopologyMatch
- 添加RBAC规则
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:kube-scheduler:plugins
rules:
- apiGroups:
- topology.crane.io
resources:
- "*"
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-scheduler:plugins
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-scheduler:plugins
subjects:
- kind: User
apiGroup: rbac.authorization.k8s.io
name: system:kube-scheduler
- 修改
kube-scheduler.yaml并用 Crane-scheduler的镜像替换 kube-scheduler 镜像
使用拓扑感知调度对Pod进行精细化调度
正确安装组件后,每个节点均会生成NodeResourceTopology对象。
$ kubectl get nrt
NAME CRANE CPU MANAGER POLICY CRANE TOPOLOGY MANAGER POLICY AGE
9.134.230.65 Static SingleNUMANodePodLevel 35d
可以看出minikube集群中节点9.134.230.65已生成对应的NRT对象,此时Crane的CPU Manager Policy为 Static,节点默认的Topology Manager Policy为 SingleNUMANodePodLevel,代表节点不允许跨NUMA分配资源。
使用以下实例进行调度测试:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
annotations:
topology.crane.io/topology-awareness: 'true' # 添加注解,表示Pod需要感知CPU拓扑,资源分配不允许跨NUMA。若不指定,则拓扑策略默认继承节点上的topology.crane.io/topology-awareness标签
topology.crane.io/cpu-policy: 'exclusive' # 添加注解,表示Pod的CPU分配策略为exclusive策略。
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "2" # 需要limits.cpu值,如果要开启绑核,则该值必须等于requests.cpu。
memory: 2Gi
从annotations中查看Pod的拓扑分配结果。发现Pod在NUMA Node0上被分配了2个CPU核心。
$ kubectl get pod -o custom-columns=name:metadata.name,topology-result:metadata.annotations."topology\.crane\.io/topology-result"
name topology-result
nginx-deployment-754d99dcdf-mtcdp [{"name":"node0","type":"Node","resources":{"capacity":{"cpu":"2"}}}]
为系统组件预留CPU
在某些场景下,我们希望能对kubelet预留的cpu做一些保护,使用场景包括但不限于:
- 在混布场景下,不希望离线任务绑定系统预留的CPU核心,防止对k8s系统组件产生影响
- 0号核心在linux有独特用途,比如处理网络包、内核调用、处理中断等,因此不希望任务绑定0号核心
在Crane中,我们可以通过以下方式为系统组件预留CPU:
kubelet设置预留CPU:按照官方指引设置预留的CPU列表- 查看
NodeResourceTopology对象,.spec.attributes中的go.crane.io/reserved-system-cpus存储了预留的CPU 列表 - 在Pod的annotations中添加
topology.crane.io/exclude-reserved-cpus,表征Pod不绑定预留的CPU核心
apiVersion: apps
kind: Deployment
metadata:
name: nginx-reserve-cpus
labels:
app: nginx-reserve-cpus
spec:
replicas: 1
selector:
matchLabels:
app: nginx-reserve-cpus
template:
metadata:
labels:
app: nginx-reserve-cpus
annotations:
topology.crane.io/exclude-reserved-cpus: "true" ##不绑定系统预留cpu核心
spec:
schedulerName: crane-scheduler
containers:
- image: nginx:latest
name: nginx
- 登录到节点上,查看Pod绑定的CPUSet, 发现Pod在被分配了共享池中除预留核心外的其他CPU核心。
# 未设置预留
$ /sys/fs/cgroup/cpuset/kubepods J# cat besteffort/pod760a7e79-4+0b-4a16-8393-0f0c253ce26c/3c6bd8251e88543235f01bacf72406c5b249edd26747cc12fd1e6fc5535edec/cpuset.cpus
0-15,20-47,52-63
# 预留0号核心
$ /sys/fs/cgroup/cpuset/kubepods ]# cat besteffort/pod6afa5fe5-ba43-490a-9fa0-034fc23f440b/b574be6egedc916517bc4feb66078d3148d29bf5db5eb2cd379873e1157c1d4/cpuset.cpus
1-15,20-47,52-63