Recommendation Framework
5 分钟阅读
Recommendation Framework provide a consistence progress to optimize variable kinds of resources in kubernetes. The progress should be Pluggable and support Multi-Cloud.
Motivation
Currently, we use Analytics and Recommendation to provide a recommendation service for workloads in cluster. Kubernetes’ users use the recommendation to optimize the resource configuration and reduce their cost.
But the recommendations have some limitations now:
- Multiple Analytics can select some same resources, it’s confused and unnecessary to have two recommendation for the same resource.
- We need to support more kinds of resources, for example, scan for idle load balancers.
- We need to make the progress Pluggable to support different user in difference clouds.
Goals
- Global analytics rules
- Easy to know the recommendation for my resource
- Consistence progress for all resource recommendation
- Plugin mechanism to support Multi-Cloud
Non-Goals
- Cloud Resources that not included in kubernetes
Proposal
User Stories
Story 1
As a Serverless customer, I want to know the suitable requests and limits for my deployments, the result should be fit the existing pod model(e.g. 2c4g, 1c1g) in my cloud production.
Story 2
As an Aliyun ACK customer, I want to know whether there is a waste of LoadBalances in my cluster and delete them if exists.
Story 3
As a container platform user, I want to integrate optimize recommendation to my platform and optimize my cluster within my CICD pipeline.
Api Definition
RecommendationRule defines which resources are required to recommend and what is the runInterval.
// RecommendationRuleSpec defines resources and runInterval to recommend
type RecommendationRuleSpec struct {
// ResourceSelector indicates how to select resources(e.g. a set of Deployments) for an Recommendation.
// +required
// +kubebuilder:validation:Required
ResourceSelectors []ResourceSelector `json:"resourceSelectors"`
// RunInterval between two recommendation
RunInterval time.Duration `json:"runInterval,omitempty"`
}
// ResourceSelector describes how the resources will be selected.
type ResourceSelector struct {
// Kind of the resource, e.g. Deployment
Kind string `json:"kind"`
// API version of the resource, e.g. "apps/v1"
// +optional
APIVersion string `json:"apiVersion,omitempty"`
// Name of the resource.
// +optional
Name string `json:"name,omitempty"`
// +optional
LabelSelector metav1.LabelSelector `json:"labelSelector,omitempty"`
}
namespace ?
Recommendation is a content holder for recommendation result. We hope that the recommendation data can be applied directly to kubernetes cluster(Recommendation as a code) and Different type recommendation have different recommendation yaml, so the content is stored in recommendation as Data.
type Recommendation struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// +kubebuilder:pruning:PreserveUnknownFields
Data runtime.RawExtension `json:"data"`
}
Recommendation Configuration
Recommendation Configuration is centralized configuration that contains every rule for universal resource optimization. It not only includes RecommendationRules that use defines but also contains RecommendationPlugins.
Phases for a recommender
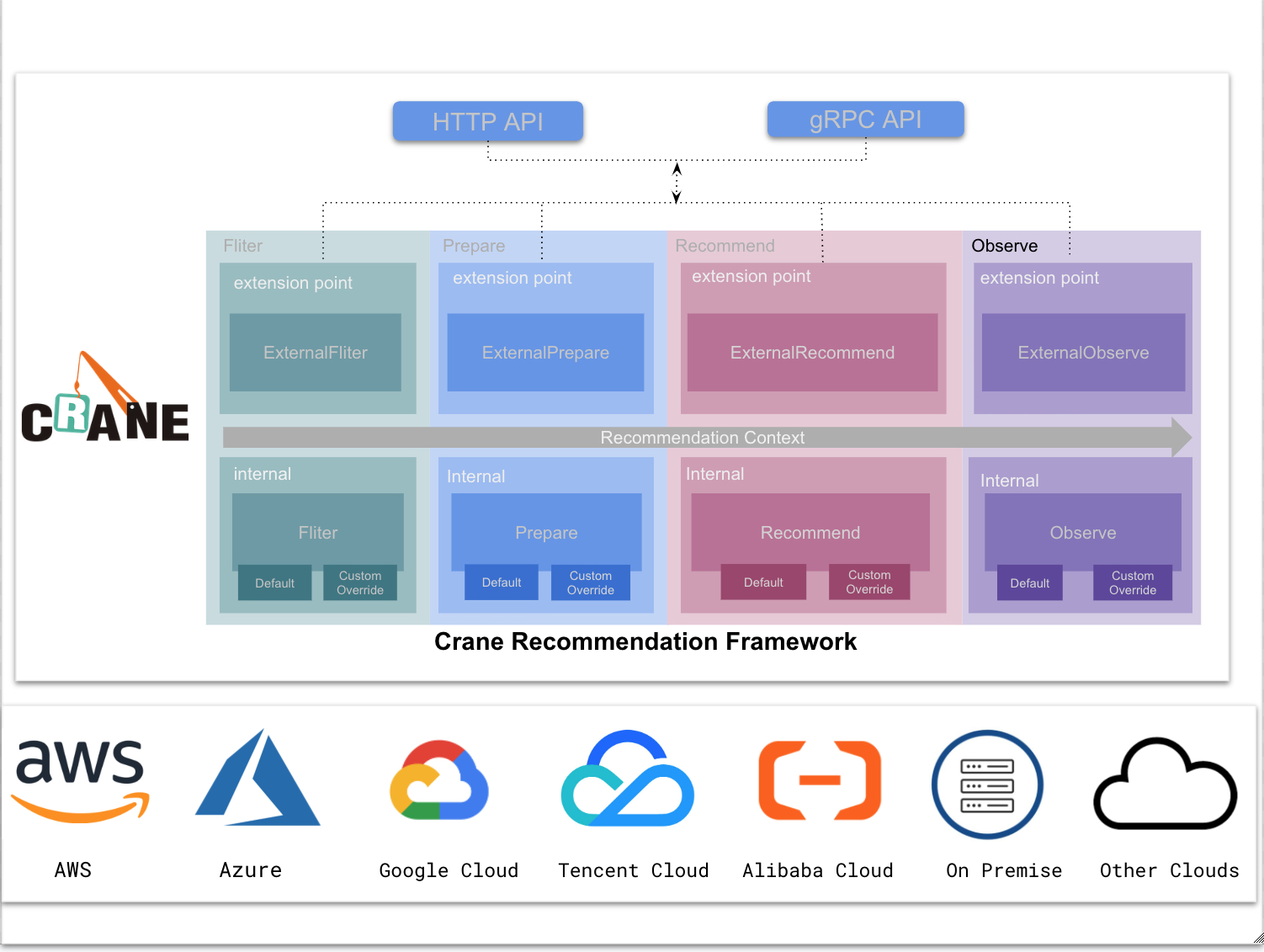
Phases
We divide the whole recommendation process into four actions, Fliter, Prepare, Recommend, Observe. The input of the whole system is the kubernetes resource you want to analyze, and the output is the best recommendation for the resource.Below we describe in detail the capabilities and input and output of each part of Recommendation Framework.
Fliter
The input of Fliter is an analysis recommendation task queue, and the queue stores the Recommendation CR submitted by the user.In default PreFliter,we will do nothing for the queue, this queue will be a FIFO queue.If you want to follow certain rules for the queue, you can implement it yourself PreFliter via extension point or override this func.In the default fliter stage, we will first filter the non-recommended resources according to the user-defined analyzable resource type. For example, the analyzable kubernetes resource I defined is deployment,ingress,node. If you submit a recommendation cr for statefulset, it will be abort in this phase.Then, we will check whether the resource you want exists, if not, we will abort.If you wish to use different filtering logic, you can implement your own logic through the fliter extension point or override it.
Prepare
Prepare is the data preparation stage, and will pull the indicator sequence within the specified time according to your recommended tasks.In PrePrepare,by default we will check the connectivity of the metrics system. And we need generate the specified metrics information for metrics server system like prometheus or metrics server. In Prepare,we will get the indicator sequence information.In PostPrepare, we will implement a data processing module.Some data processing such as data correction for cold start application resource glitch, missing data padding, data aggregation,deduplication or noise reduction. The output of whole will be normalized to a specified data type.Of course you can also implement your own PrePrepare, Prepare, PostPrepare logic.
Recommend
The input of Recommend is a data sequence, and the output is the result of the recommendation type you specify. For example, if your recommendation type is resource, the output is the recommended size of the resource of the kubernetes workload you specified.In Recommend, we will apply crane’s algorithm library to your data sequence.And in PostRecommend,We will use some strategies to regularize the results of the algorithm. For example, if a margin needs to be added when recommending resources, it will be processed at this stage.You can implement your own Recommend logic via extension points or override it.
Observe
Observe is to intuitively reflect the effectiveness of the recommendation results. For example, when making resource recommendations, users not only care about the recommended resource configuration, but also how much cost can be saved after modifying the resource configuration. In PreObserver, we will check the cloud api connectivity and establish link with cloud vendor’s billing system. And in Observe we will turn resource optimization into cost optimization.You can implement your own Observe logic via extension points or override it.