Application Resource Optimize Model
Application Resource Optimize Model
2 minute read
Resource optimization is a common optimization strategy in FinOps. Based on the characteristics of Kubernetes applications, we have summarized the resource optimization model for cloud-native applications:
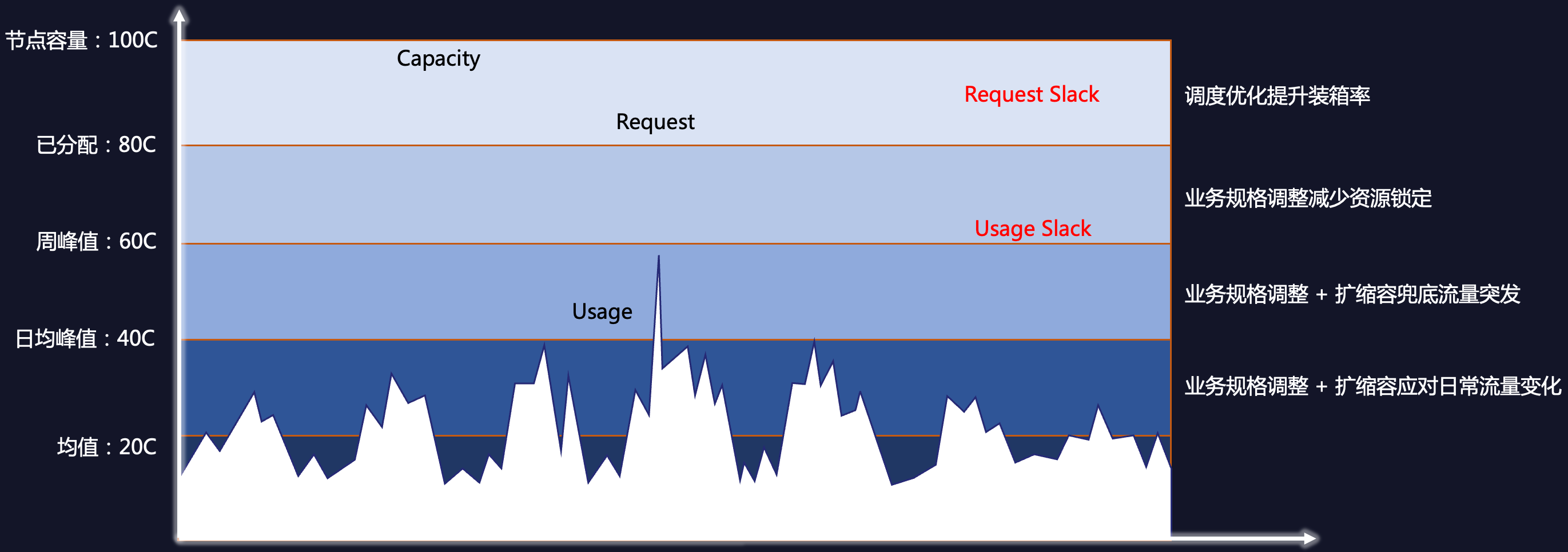
The five lines in the figure from top to bottom are:
- Node capacity: the total resources of all nodes in the cluster, corresponding to the Capacity of the cluster
- Allocated: the total resources applied by the application, corresponding to Pod Request
- Weekly peak usage: the peak resource usage of the application in the past period. The weekly peak can predict the resource usage in the future period. Configuring resource specifications based on weekly peak can ensure higher security and stronger versatility.
- Daily peak usage: the peak resource usage of the application in one day
- Average usage: the average resource usage of the application, corresponding to Usage
There are two types of idle resources:
- Resource Slack: the difference between Capacity and Request
- Usage Slack: the difference between Request and Usage
Total Slack = Resource Slack + Usage Slack
The goal of resource optimization is to reduce Resource Slack and Usage Slack. The model provides four steps for reducing waste, from top to bottom:
- Improve packing rate: improving packing rate can make Capacity and Request closer. There are many methods, such as dynamic scheduler, Tencent Cloud native node’s node enlargement function, etc.
- Adjust application requests to reduce resource locking: adjust application specifications based on the weekly peak resource usage to reduce Request to the weekly peak line. Resource recommendation and replica recommendation can help applications achieve this goal.
- Application requests adjustment + scaling to cope with sudden traffic bursts: based on the request optimization, use HPA to cope with sudden traffic bursts, and reduce Request to the daily average peak line. At this time, the target utilization rate of HPA is low, only for coping with sudden traffic, and autoscaling does not occur most of the time. HPA recommendation can scan out applications suitable for elasticity and provide HPA configuration.
- Application requests adjustment + scaling to cope with daily traffic changes: based on the request optimization, use HPA to cope with daily traffic and reduce Request to the average. At this time, the target utilization rate of HPA is equal to the average utilization rate of the application. EHPA provide prediction-based horizontal elasticity, helping more applications achieve intelligent elasticity.