How to optimize your application in FinOps era
14 minute read
As more and more enterprises migrate their applications to the Kubernetes platform, it has gradually become an important entry point for resource orchestration and scheduling. As we all know, Kubernetes schedules applications based on the resource quotas requested by the applications, so how to properly configure application resource specifications has become the key to improving cluster utilization. This article will share how to correctly configure application resources based on the FinOps open-source project Crane, and how to promote resource optimization practices within the enterprise.
Kubernetes How to manage resources
Pod Resource model
In Kubernetes, the desired amount of resources for a Pod can be selectively set by specifying Request/Limit. When the resource Request is specified for a Container in a Pod, Kube-scheduler uses this information to determine which node to schedule the Pod on. When the resource Request and Limit are specified for a Container, kubelet ensures that the running container can access the requested resources through Cgroup parameters and does not use resources beyond the set limit. Kubelet also reserves system resources equal to the Request amount for the container to use. example of resource configuration for a Pod:
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Once the resource request amount is determined, the resource utilization formula for an application can be derived as follows: Utilization = Resource Usage / Resource Request.
Therefore, to improve the utilization of Pods, we need to configure reasonable resource requests.
Workload Resource model
A workload is an application that runs on Kubernetes, consisting of a group of Pods, such as Deployments and StatefulSets. The number of Pods is referred to as the workload’s replica count.
The resource utilization formula for a workload is: Workload Utilization = (Pod1 Usage + Pod2 Usage + … PodN Usage) / (Request * Replicas).
As the formula shows, improving workload utilization can not only reduce the Request, but also reduce the Replicas.
Common resource configuration issues
The Canadian software company Densify summarized common resource configuration issues in “12 RISK OF KUBERNETES RESOURCE MANAGEMENT” [1]. In the table below, we have added an analysis dimension of replica counts based on their findings.
| CPU Request | Memory Request | CPU Limit | Memory Limit | Replicas | |
|---|---|---|---|---|---|
| Oversized | Excess CPU resources lead to more waste of nodes and resources | K8s scheduler may request excessive Memory resources, leading to more waste of nodes and resources. | Allowing Pods to request excessive CPU resources can create a ’noisy neighbor’ risk, affecting other Pods on the same node | Allowing Pods to request excessive Memory resources can create a ’noisy neighbor’ risk, which in turn can affect other Pods running on the same node | Excessive Pods can lead to more waste of nodes and resources |
| Undersized | This can lead to excessive stacking of Pods on nodes, and if all CPU resources are exhausted, it can result in contention and risk of CPU throttling at the node level | This can lead to excessive stacking of Pods on nodes, and if all Memory resources are exhausted, it can result in the risk of Pod termination (OOM Killer) at the node level | The Pod’s CPU usage will be limited, and if the actual workload exceeds the limit, it can result in CPU throttling and performance degradation | The Pod’s Memory usage will be limited, and if the actual workload exceeds the limit, it can trigger the OOM Killer to terminate processes | Having too few Pods can result in high utilization rates, leading to stability issues such as performance degradation and OOM Killer |
| Unset | K8s scheduler will be uncertain about how many Pods can be scheduled in the cluster, and excessive stacking of Pods can create significant performance risks and uneven workloads | The scheduler will be uncertain about how many Pods can be scheduled in the cluster, which can lead to excessive stacking and the risk of Pods being OOM killed | Unconstrained Pods can amplify the ’noisy neighbor’ effect and create the risk of CPU throttling | Unconstrained Pods can amplify the ’noisy neighbor’ risk, and if the node’s memory is exhausted, it can trigger the OOM Killer to terminate processes | N/A |
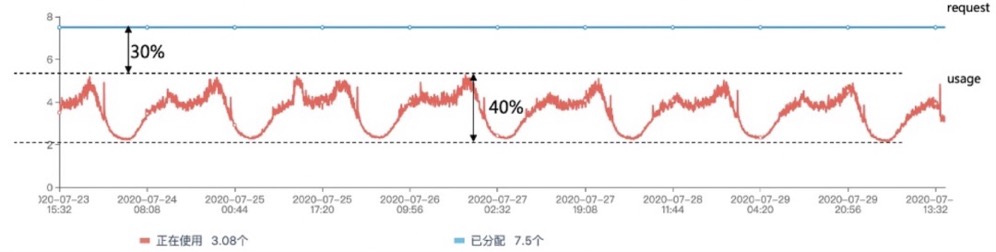
As we can see, setting resource limits too low can lead to stability issues, while setting them too high only results in “mere” resource waste, which can be acceptable during periods of rapid business growth. This is the main reason why resource utilization rates are generally low for many businesses after migrating to the cloud. The following graph shows the resource usage of an application, with 30% resource waste between the peak historical usage of the Pod and its Request amount.
Application Resource Optimization Model
After mastering Kubernetes’ resource model, we can further derive a resource optimization model for cloud-native applications:
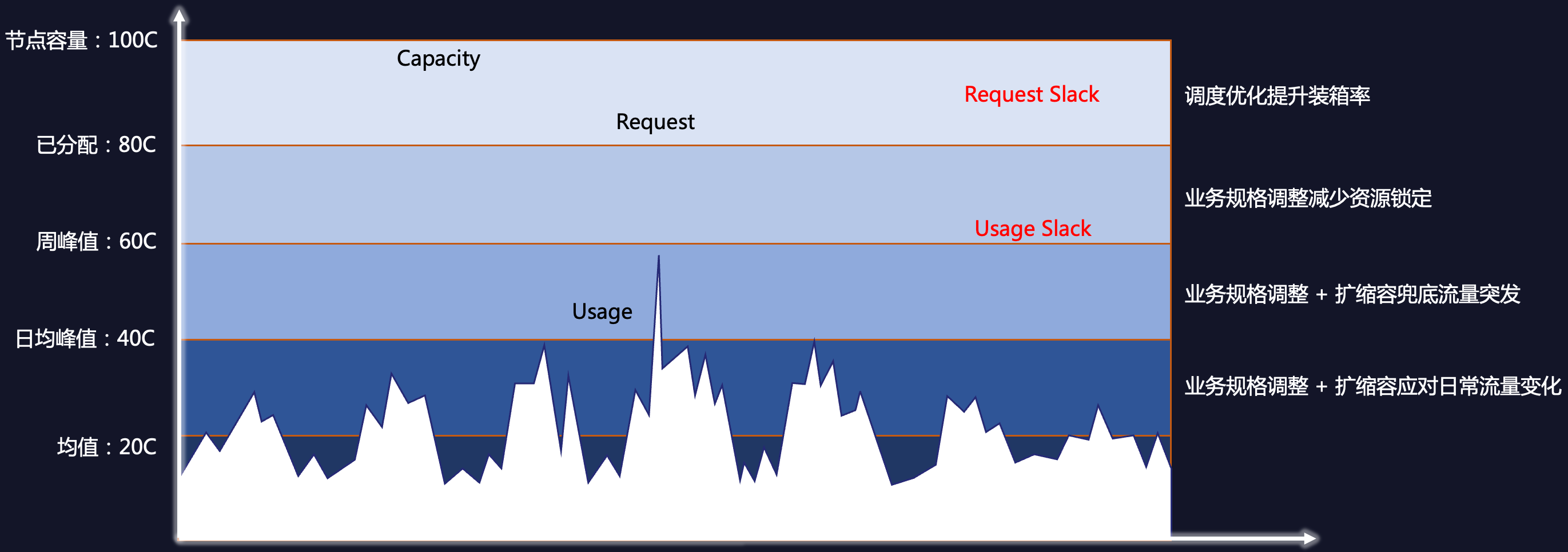
The five lines in the graph from top to bottom are:
- Node Capacity: The total amount of resources in all nodes in the cluster, corresponding to the Capacity of the cluster.
- Allocated: The total amount of resources allocated by the application, corresponding to the Pod Request.
- Weekly Peak: The peak resource usage of the application during a certain period in the past. Weekly peak can be used to predict future resource usage, and configuring resource specifications based on weekly peak has higher security and more general applicability.
- Daily Average Peak: The peak resource usage of the application in the past day.
- Mean: The average resource usage of the application, corresponding to Usage.
The idle resources can be divided into two categories:
- Resource Slack: The difference between Capacity and Request.
- Usage Slack: The difference between Request and Usage.
Total Slack = Resource Slack + Usage Slack
The goal of resource optimization is to reduce Resource Slack and Usage Slack. The model provides four steps for reducing waste, in order from top to bottom:
- Improving packing rate: Improving the packing rate can bring the Capacity and Request closer together. There are many ways to achieve this, such as:Dynamic scheduler、Tencent Cloud Native Node’s node amplification function, etc.
- Adjusting business specifications to reduce resource locking: Adjusting business specifications based on the weekly peak resource usage can reduce the Request to the weekly peak line.Resource recommendation and Replicas Recommendationcan help applications achieve this goal.
- Adjusting business specifications + scaling to handle burst traffic: Based on the optimization of specifications, HPA can handle burst traffic to reduce the Request to the daily peak line. At this time, the target utilization rate of HPA is low, only to handle burst traffic, and automatic elasticity does not occur most of the time.
- Adjusting business specifications + scaling to handle daily traffic changes: Based on the optimization of specifications, HPA can handle daily traffic to reduce the Request to the mean. At this time, the target utilization rate of HPA is equal to the average utilization rate of the application.
Based on this model, the open-source project Crane provides dynamic scheduling, recommendation framework, intelligent elasticity, and mixed deployment capabilities, realizing an all-in-one FinOps cloud resource optimization platform. In this article, we will focus on the recommendation framework.
Optimizing resource configuration through the Crane recommendation framework
The open-source project Crane has launched the Recommendation Framework, which automatically analyzes the operation of various resources in the cluster and provides optimization suggestions. By analyzing CPU/Memory monitoring data over a period of time and using resource recommendation algorithms, the Recommendation Framework provides resource configuration suggestions, allowing enterprises to make decisions based on the proposed configurations.
In the following example, we will demonstrate how to quickly start a full cluster resource recommendation.
Before embarking on this cost-cutting journey, you need to install Crane in your environment. Please refer to Crane’s installation documentation for guidance.
Create RecommendationRule
Here’s a RecommendationRule example: workload-rule.yaml。
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
metadata:
name: workloads-rule
spec:
runInterval: 24h # run once every 24 hours
resourceSelectors: # information about resources
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
namespaceSelector:
any: true # scan all namespaces
recommenders: # Use replica and resource recommenders for Workloads
- name: Replicas
- name: Resource
In this example:
- Analysis recommendations are run every 24 hours, with the runInterval format set as an interval of time, such as 1h or 1m. Setting it to empty means running only once.
- The resources to be analyzed are set through the resourceSelectors array. Each resourceSelector selects resources in the k8s cluster based on kind, apiVersion, and name. When name is not specified, it means all resources under the namespaceSelector.
- The namespaceSelector defines the namespaces of the resources to be analyzed. “any: true” means selecting all namespaces.
- The recommenders define which Recommender(s) should be used for analyzing the resources. Currently supported types are: recommenders.
- The resource types and recommenders need to be matched. For example, the Resource Recommender only supports Deployments and StatefulSets by default. Please refer to the recommender’s documentation for which resource types each Recommender supports.
- Create a RecommendationRule with the following command, and the recommendation will start immediately after creation.
kubectl apply -f workload-rules.yaml
This example will perform resource and replica recommendations for Deployments and StatefulSets in all namespaces. 2. Check the recommendation progress of the RecommendationRule. Observe the progress of the recommendation task through Status.recommendations. The recommendation tasks are executed sequentially. If the lastStartTime of all tasks is the latest time and the message has a value, it indicates that the current recommendation has been completed.
kubectl get rr workloads-rule
- Query the recommendation results with the following command:
kubectl get recommend
You can filter the Recommendation by the following labels, for example: kubectl get recommend -l analysis.crane.io/recommendation-rule-name=workloads-rule
Adjust resource configurations based on optimization recommendations from the Recommendation.
For resource and replica recommendations, users can PATCH status.recommendedInfo to the Workload to update the resource configurations. For example:
patchData=`kubectl get recommend workloads-rule-replicas-rckvb -n default -o jsonpath='{.status.recommendedInfo}'`;kubectl patch Deployment php-apache -n default --patch "${patchData}"
Recommender
Currently, Crane supports the following Recommenders:
- Resource Recommendation: By using the VPA algorithm to analyze the actual usage of applications, Crane recommends more appropriate resource configurations.
- Replicas Recommendation: By using the HPA algorithm to analyze the actual usage of applications, Crane recommends more appropriate replica numbers.
- HPA Recommendation: Scan the Workloads in the cluster and recommend HPA configurations for Workloads that are suitable for horizontal scaling.
- Idlenode Recommendation: By scanning the state and utilization of nodes in the cluster, Node recommendation helps users find idle Kubernetes nodes.
- Service Recommendation: By scanning the running status of Services in the cluster, Service recommendation helps users find idle Kubernetes Services.
- PV Recommendation: By scanning the running status of PV in the cluster, PV recommendation helps users find idle Kubernetes PV.
This article focuses on optimizing resource configurations for Workloads, therefore, the following section will focus on resource recommendations and replica recommendations.
Resource recommendations
Here’s an example of resource recommendations:
status:
recommendedInfo: >-
{"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}}]}}}}
currentInfo: >-
{"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"500m","memory":"512Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"200m","memory":"256Mi"}}}]}}}}
action: Patch
conditions:
- type: Ready
status: 'True'
lastTransitionTime: '2022-11-29T04:07:44Z'
reason: RecommendationReady
message: Recommendation is ready
lastUpdateTime: '2022-11-30T03:07:49Z'
recommendedInfo displays the recommended resource configuration, while currentInfo displays the current resource configuration. The format is JSON, and the recommended results can be updated to TargetRef using Kubectl Patch.
Compute resource specification algorithm
The resource recommendation process is completed in the following steps:
- Obtain the CPU and memory usage history of the workload in the past week through monitoring data.
- Based on the historical usage, use the VPA Histogram to take the P99 percentile and multiply it by an amplification factor.
- OOM Protection: If there have been historical OOM events in the container, consider increasing memory appropriately when making memory recommendations.
- Resource Specification Regularization: Round up the recommended results to the specified container specifications. The basic principle is to set the Request slightly higher than the maximum historical usage based on historical resource usage, and consider factors such as OOM and Pod specifications.
Replica recommendations
Here’s an example of replica recommendations:
status:
recommendedInfo: '{"spec":{"replicas":1}}'
currentInfo: '{"spec":{"replicas":2}}'
action: Patch
conditions:
- type: Ready
status: 'True'
lastTransitionTime: '2022-11-28T08:07:36Z'
reason: RecommendationReady
message: Recommendation is ready
lastUpdateTime: '2022-11-29T11:07:45Z'
The recommendedInfo displays the recommended replica count, and the currentInfo displays the current replica count in JSON format. The recommended results can be updated to TargetRef using Kubectl Patch.
The replica recommendation process is completed in the following steps:
- Obtain the CPU and memory usage history of the workload in the past week through monitoring data.
- Use the DSP algorithm to predict the future CPU usage for the next week.
- Calculate the replica count for CPU and memory separately, and take the larger value.
Compute replica algorithm
Taking CPU as an example, assuming that the P99 of the historical CPU usage of the workload is 10 cores, and the Pod CPU Request is 5 cores, the target peak utilization is 50%. It can be inferred that 4 replicas are needed to meet the requirement of the peak utilization not being less than 50%.
replicas := int32(math.Ceil(workloadUsage / (TargetUtilization * float64(requestTotal))))
Differences with the community
According to the resource optimization model, the recommendation framework can reduce the Request of the application to the weekly peak, and the recommendation framework only provides specification recommendations without executing changes, which is more secure and applicable to more business types. If further Request reduction is needed, HPA and other solutions can be considered.
| utilization rate | management configuration type | change type | |
|---|---|---|---|
| Community HPA | average utilization rate | replica number | automatic scaling |
| Community VPA | approximate peak utilization rate | resource Request | automatic scaling/recommendation |
| Crane recommendation framework | weekly peak utilization rate | replica number + resources Request | automatic scaling/recommendation |
| advantages of the recommendation framework | Although the weekly peak utilization rate provides relatively small cost reduction space, it is simple to configure, safer, and applicable to more types of applications. | Both replica number and resource Request can be recommended simultaneously, and adjustments can be made as needed. | Provide recommendation suggestions through CRD/Metric, which is convenient for integration into user systems. In the future, it will support automatic updates through CICD |
Best practices
FinOps recommends using an iterative approach to manage variable costs of cloud services. The continuous management iteration consists of three phases: cost observation (Inform), cost analysis (Recommend), and cost optimization (Operate). In the following section, we will introduce how to use Crane for K8S resource configuration management based on these three phases and the internal practice experience of Tencent.
Cost Monitoring–Calculating Costs/Benefits
Cost observation is the core key to the cost reduction journey. Only by setting clear goals can cost reduction optimization be targeted. Therefore, users need to establish a monitoring and observation system for cluster resources to evaluate whether cost reduction and efficiency improvement are necessary. For example, what is the packing rate of the cluster? What is the average/peak utilization rate of the cluster? What is the resource usage distribution of each Namespace, and what is the average/peak utilization rate of each Workload?
Cost Analysis–Establishing Systems
The Crane recommendation framework provides a complete set of analysis and optimization tools for full-fledged analysis of cluster resources, and records the recommended results in CRD and Metrics for easy integration into business systems.
The practice within Tencent is as follows:
- Use RecommendationRule to recommend resources and replicas for all workloads in the cluster, updated every 12 hours.
- Display the complete recommendation results separately in the control interface.
- Display resource/replica recommendations on the workload data display page.
- Display observation data of the workload in Grafana charts.
- Provide OpenAPI for businesses to obtain recommendations and optimize them according to business needs.
Cost Optimization–Progressive Recommendations
The FinOps Foundation has defined a “crawl, walk, run” maturity method for FinOps, enabling enterprises to start small and gradually expand in scale, scope, and complexity. Similarly, the premise of cost reduction is to ensure stability, as changes in resource configuration and unreasonable configurations may affect business stability. User optimization processes should follow the same approach:
- Verify the accuracy of the configuration in the CI/CD environment before updating the production environment.
- Optimize businesses with severe waste first, and then optimize businesses with relatively low configurations.
- Optimize non-core businesses first, and then optimize core businesses.
- Configure recommended parameters based on business characteristics: Online businesses require more resource buffers, while offline businesses can accept higher utilization rates.
- The release platform prompts users with recommended configurations and updates only after confirmation to prevent unexpected online changes.
- Some business clusters automatically update workload configurations based on recommended suggestions to achieve higher utilization rates.
In the book “Cloud FinOps” which introduces FinOps, it shares an example of a Fortune 500 company optimizing resources through an automated system, with the following workflow:
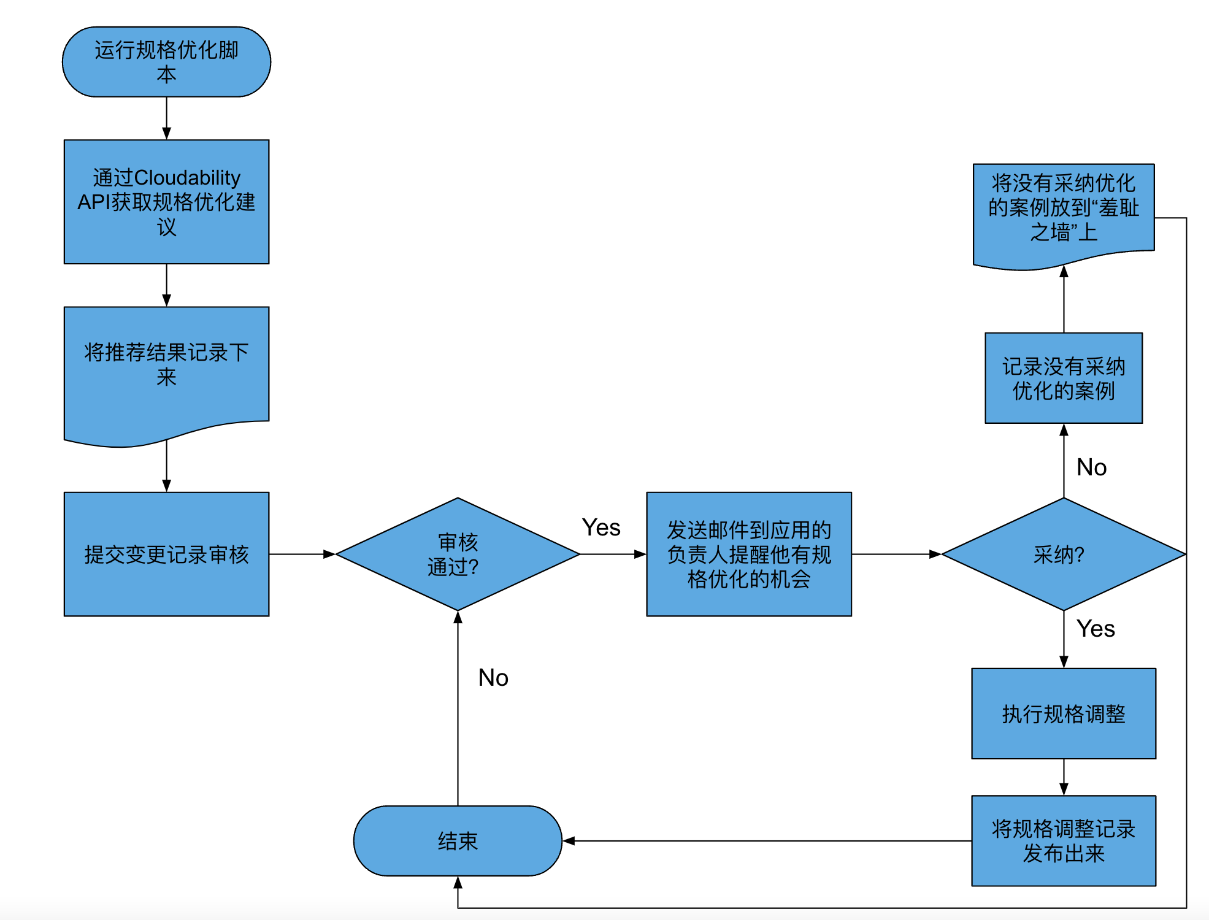
Automated configuration optimization is considered an advanced stage in FinOps and is recommended for use in the advanced stages of FinOps implementation. However, you should consider tracking the recommendations and have the corresponding team manually implement the necessary changes.
Roadmap
Whether or not resource optimization is needed, Crane can be used as a trial object when practicing FinOps. You can first understand the current state of the Kubernetes cluster through cost display, and choose the optimization method based on the problem. Resource configuration optimization, as introduced in this article, is the most direct and common method.
In the future, the Crane recommendation framework will evolve towards more accurate, intelligent, and rich goals:
-Integration with CI/CD frameworks: Automated configuration updates can further improve utilization rates compared to manual updates and are suitable for business scenarios with higher resource utilization rates. -Cost left shift: Discover and solve resource waste earlier through configuration optimization in the CI/CD stage. -Configuration recommendation based on application load characteristics: Identify load patterns and burst tasks based on algorithms and provide reasonable recommendations. -Resource recommendation for task types: Currently, more support is provided for long-running online businesses, but resource recommendations can also optimize configuration for task-type applications. -Analysis of more types of idle resources in Kubernetes: Scan idle resources in the cluster, such as Load Balancer/Storage/Node/GPU.
Appendix
1.The Top 12 Kubernetes Resource Risks: K8s Best Practices: Top 12 Kubernetes Resource Risks