Replicas Recommendation
4 minute read
Kubernetes’ users often set the replicas based on empirical values when creating application resources. Based on the replicas recommendation, you can analyze the actual application usage and recommend a more suitable replicas configuration. You can use it to improve the resource utilization of the cluster.
Motivation
Kubernetes workload replicas allows you to control the Pods for quick scaling. However, how to set a reasonable replicas has always been a problem for application administrators. Too large may lead to a lot of waste of resources, while too low may cause stability problems.
The HPA in community provides a dynamic autoscaling mechanism based on realtime metrics, meanwhile Crane’s EffectiveHPA supports prediction-driven autoscaling based on HPA. However, in the real world, only some workloads can scale horizontally all the time, many workloads require a fixed number of pods.
The figure below shows a workload with low utilization, it has 30% of the resource wasted between the Pod’s peak historical usage and its Request.
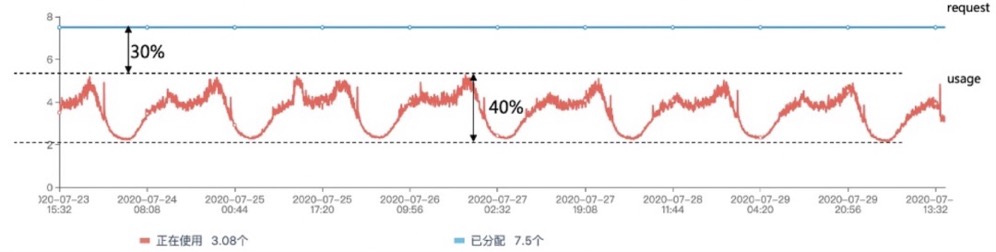
Replica recommendation attempts to reduce the complexity of how to know the replicas of workloads by analyzing the historical usage.
Sample
A Replicas recommendation sample yaml looks like below:
kind: Recommendation
apiVersion: analysis.crane.io/v1alpha1
metadata:
name: workloads-rule-replicas-p84jv
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
analysis.crane.io/recommendation-rule-name: workloads-rule
analysis.crane.io/recommendation-rule-recommender: Replicas
analysis.crane.io/recommendation-rule-uid: 18588495-f325-4873-b45a-7acfe9f1ba94
k8s-app: kube-dns
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: CoreDNS
ownerReferences:
- apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
name: workloads-rule
uid: 18588495-f325-4873-b45a-7acfe9f1ba94
controller: false
blockOwnerDeletion: false
spec:
targetRef:
kind: Deployment
namespace: kube-system
name: coredns
apiVersion: apps/v1
type: Replicas
completionStrategy:
completionStrategyType: Once
adoptionType: StatusAndAnnotation
status:
recommendedValue:
replicasRecommendation:
replicas: 1
targetRef: { }
recommendedInfo: '{"spec":{"replicas":1}}'
currentInfo: '{"spec":{"replicas":2}}'
action: Patch
conditions:
- type: Ready
status: 'True'
lastTransitionTime: '2022-11-28T08:07:36Z'
reason: RecommendationReady
message: Recommendation is ready
lastUpdateTime: '2022-11-29T11:07:45Z'
In this sample:
- Recommendation TargetRef point to a Deployment in kube-system namespace:coredns
- Recommendation type is Replicas
- adoptionType is StatusAndAnnotation,indicated that put recommendation result in recommendation.status and Deployment 的 Annotation
- recommendedInfo shows the recommended replicas(recommendedValue is deprecated),currentInfo shows the current replicas.The format is Json that can be updated for TargetRef by
Kubectl PatchTargetRef
How to create a Replicas recommendation please refer to:Recommendation Framework
Implement
The process for one Replicas recommendation:
- Query the historical CPU and Memory usage of the Workload for the past week by monitoring system.
- Use DSP algorithm to predict the CPU usage in the future.
- Calculate the replicas for both CPU and memory, then choose a larger one.
Algorithm
Use cpu usage as an example. Assume that the P99 of the historical CPU usage of the workload is 10 cores, the Pod CPU Request is 5 cores, and the target peak utilization is 50%. Therefore, we know that 4(10 / 50% / 5) pods can meet the target peak utilization.
replicas := int32(math.Ceil(workloadUsage / (TargetUtilization * float64(requestTotal))))
Abnormal workloads
The following types of abnormal workloads are not recommended:
- workload with low replicas: If the replicas is too low, it may not have high recommendation demand. Associated configuration: ‘workload-min-replicas’
- There is a certain percentage of the not running pods for workload: if the Pod of workload mostly can’t run normally, may not be suitable for recommendation, associated configuration:
pod-min-ready-seconds|pod-available-ratio
Prometheus Metrics
Record recommended replicas to Metric: crane_analytics_replicas_recommendation
How to verify the accuracy of recommendation results
Users can get the Workload resource usage through the following Prom-query, when you get the workload usage, put it into the algorithm above.
Taking Deployment Craned in crane-system as an example, you can use your container, namespace to replace it in following Prom-query.
sum(irate(container_cpu_usage_seconds_total{namespace="crane-system",pod=~"^craned-.*$",container!=""}[3m])) # cpu usage
sum(container_memory_working_set_bytes{namespace="crane-system",pod=~"^craned-.*$",container!=""}) # memory usage
Accepted resources
Support StatefulSet and Deployment by default,but all workloads that support Scale SubResource are supported.
Configuration
| Configuration items | Default | Description |
|---|---|---|
| workload-min-replicas | 1 | Workload replicas that less than this value will abort recommendation |
| pod-min-ready-seconds | 30 | Defines the min seconds to identify Pod is ready |
| pod-available-ratio | 0.5 | Workload ready Pod ratio that less than this value will abort recommendation |
| default-min-replicas | 1 | default minReplicas |
| cpu-percentile | 0.95 | Percentile for historical cpu usage |
| mem-percentile | 0.95 | Percentile for historical memory usage |
| cpu-target-utilization | 0.5 | Target of CPU peak historical usage |
| mem-target-utilization | 0.5 | Target of Memory peak historical usage |
How to update recommendation configuration please refer to:Recommendation Framework